久违了,朋友们,来篇干货。
ETL 的全称是 extract, transform, load,意思就是:提取、转换、 加载。ETL 是数据分析中的基础工作,获取非结构化或难以使用的数据,把它变为干净、结构化的数据,比如导出 csv 文件,为后续的分析提供数据基础。
1、提取数据
这里从电影数据 API 请求数据。在开始之前,你需要获得 API 密钥来访问 API可以在这里[1]找到获取密钥的说明。
一旦你有了密钥,需要确保你没有把它直接放入你的源代码中,因此你需要创建 ETL 脚本的同一目录中创建一个名为 config.py 的文件,将此放入文件:
#config.py
api_key =
如果要将代码发布到任何地方,应该将 config.py 放入 .gitignore 或类似文件中,以确保它不会被推送到任何远程存储库中。
还可以将 API 密钥存储为环境变量,或使用其他方法隐藏它。目标是保护它不暴露在 ETL 脚本中。
现在创建一个名为 tmdb.py 的文件,并导入必要的依赖:
import pandas as pd
import requests
import config
向 API 发送单个 GET 请求的方法。在响应中,我们收到一条 JSON 记录,其中包含我们指定的 movie_id:
API_KEY = config.api_key
url = 'https://api.themoviedb.org/3/movie/{}?api_key={}'.format(movie_id, API_KEY)
r = requests.get(url)
这里我们请求 6 部电影,电影 movie_id 从 550 到 555 不等。我们创建一个循环,一次请求每部电影一部,并将响应附加到列表中:
response_list = []
API_KEY = config.api_key
for movie_id in range(550,556):
url = 'https://api.themoviedb.org/3/movie/{}?api_key={}'.format(movie_id, API_KEY)
r = requests.get(url)
response_list.append(r.json())
现在我们拿到了 response_list 这样复杂冗长的 JSON 数据,这里使用 from_dict() 从记录中创建 Pandas 的 DataFrame 对象:
df = pd.DataFrame.from_dict(response_list)
如果在 jupyter 上输出一下 df,你会看到这样一个数据帧:
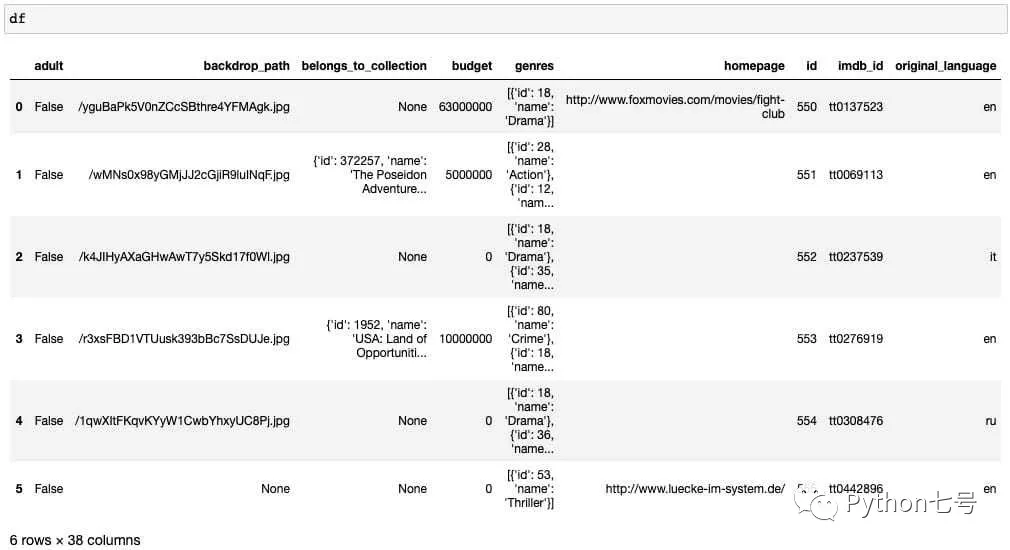
至此,数据提取完毕。
2、转换
我们并不需要提取数据的所有这些列,所以接下来选择我们需要使用的列。
假如以下列是我们感兴趣的:
budget
id
imdb_id
genres
original_title
release_date
revenue
runtime
创建一个名为 df_columns 的列名称列表,以便从主数据帧中选择所需的列。
df_columns = ['budget', 'genres', 'id', 'imdb_id', 'original_title', 'release_date', 'revenue', 'runtime']
请注意,有一个 genres 列(表示电影的体裁,类型)是长这样的:

这是一个 JSON 格式的列,我们希望扩展它。
一种比较直观的方法是将 genres 内的分类分解为多个列,如果某个电影属于这个分类,那么就在该列赋值 1,否则就置 0,就像这样:
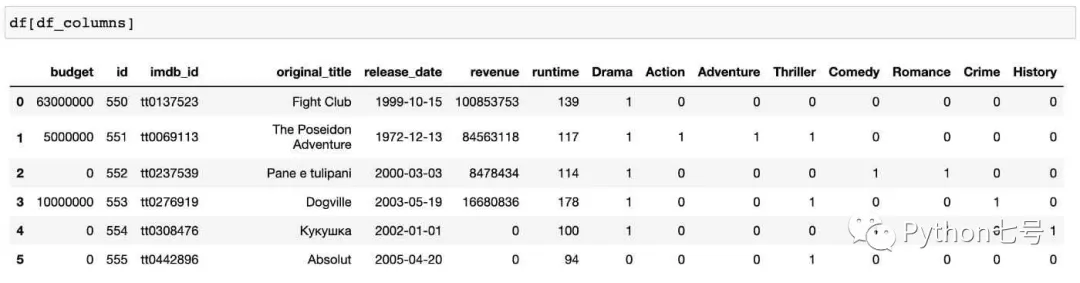
现在我们用 pandas 来实现这个扩展效果。
首先扁平化这个 JSON 列表:
genres_list = df['genres'].tolist()
flat_list = [item for sublist in genres_list for item in sublist]
接下来,我们创建一个 genres_all 的临时列,作为电影类别的代表,我们只需要 genres 内的 name 属性,稍后把它扩展为单独的列:
result = []
for l in genres_list:
r = []
for d in l:
r.append(d['name'])
result.append(r)
df = df.assign(genres_all=result)
为了完整的保存 genres 类型表,我们把它单独做为一个表:电影类型表:
df_genres = pd.DataFrame.from_records(flat_list).drop_duplicates()
它是这样的:

接下来,将类型名称附加到 df_columns 中,然后删除 genres 列:
df_columns = ['budget', 'id', 'imdb_id', 'original_title', 'release_date', 'revenue', 'runtime']
df_genre_columns = df_genres['name'].to_list()
df_columns.extend(df_genre_columns)
s = df['genres_all'].explode()
df = df.join(pd.crosstab(s.index, s))
代码的最后两行,使用了 explode、crosstab 函数来扩展多个列,其效果就是如果电影属于某个类型,该行的值就为 1,结果就是这样: 
关于日期时间,我们希望将日期扩展为年、月、日、周,像这样:
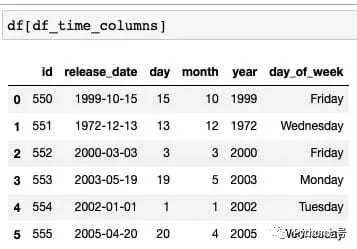
那么以下代码就是干这个的:
df['release_date'] = pd.to_datetime(df['release_date'])
df['day'] = df['release_date'].dt.day
df['month'] = df['release_date'].dt.month
df['year'] = df['release_date'].dt.year
df['day_of_week'] = df['release_date'].dt.day_name()
df_time_columns = ['id', 'release_date', 'day', 'month', 'year', 'day_of_week']3、加载
加载就很简单了,将 DataFrame 导出到 excel 或者 csv 即可。
df[df_columns].to_csv('tmdb_movies.csv', index=False)
df_genres.to_csv('tmdb_genres.csv', index=False)
df[df_time_columns].to_csv('tmdb_datetimes.csv', index=False)
如果要导出 excel,那么就用 to_excel 函数。
最后的话
Pandas 是处理 excel 或者数据分析的利器,ETL 必备工具,本文以电影数据为例,分享了 Pandas 的常见用法。
本文链接:http://www.28at.com/showinfo-119-2165-0.html用 Pandas 做 ETL,不要太快
声明:本网页内容旨在传播知识,若有侵权等问题请及时与本网联系,我们将在第一时间删除处理。邮件:2376512515@qq.com
Copyright © 2016-2023 天津谷骐科技有限公司 版权所有 sitemap.xml
违法及侵权请联系:2376512515@qq.com 津ICP备18001702号
 津公网安备 12010102000574号
津公网安备 12010102000574号
